Artificial intelligence
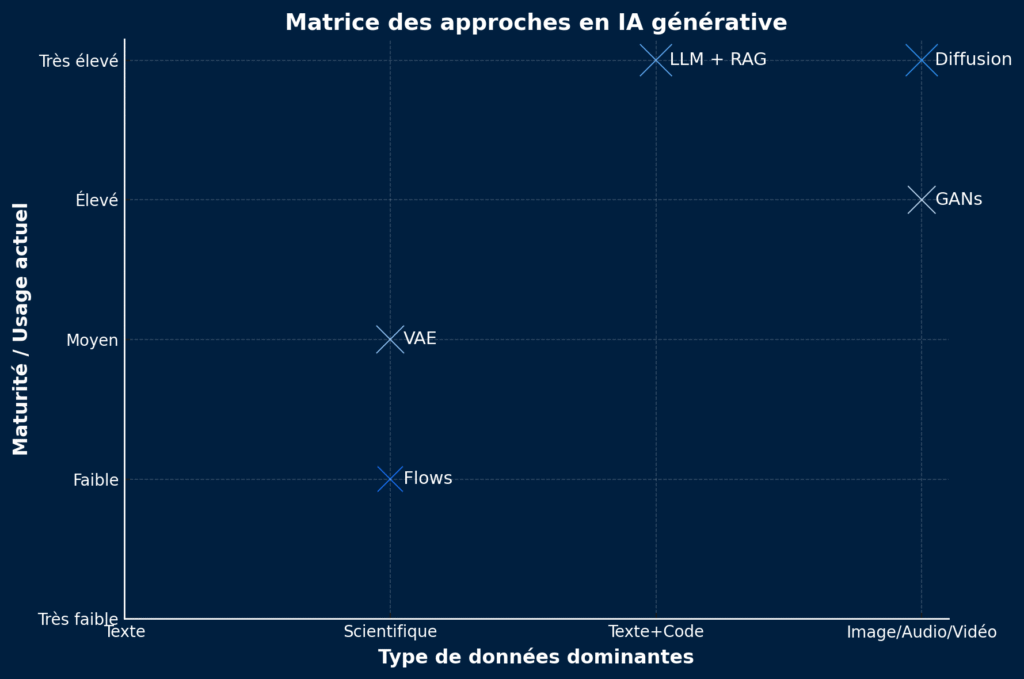
Different approaches to generative AI
Publiée le September 24, 2025
Publiée le September 24, 2025
Generative artificial intelligence is based on several major families of models, each with its own mechanisms, strengths and limitations. Here are the approaches most commonly used today.
Large language models are mainly used for :
Text generation (articles, marketing content, conversational responses).
Assisted programming and code generation.
Writing summaries, notes or reports.
Intelligent chatbots and business assistants.
An LLM predicts the next word or token in a sequence based on the previous ones. However, these models can “hallucinate”, producing erroneous information. To overcome this problem, we combine LLM with RAG (Retrieval-Augmented Generation): before responding, the model queries an external document base (internal documents, databases, websites) to enrich its generation with real, up-to-date facts.
Ability to respond to concrete business needs: automation, information retrieval, customer support.
RAG improves reliability and reduces factual errors.
Flexible integration into a variety of business environments.
ChatGPT (GPT-4), Anthropic’s Claude, or LLaMA combined with a RAG module.
Today, these models dominate the generation of visual and multimedia content:
Realistic images and illustrations.
Short or long videos.
Audio and voice.
3D objects and scenes.
Diffusion works in the opposite direction to noise. We start with a random, noisy image, and the model learns to “clean” it up step by step, until it produces a coherent, faithful image.
Exceptional visual quality, capable of rivaling photographs.
Highly creative: ideal for design, marketing, architecture or entertainment.
High adoption in the creative industries thanks to accessible tools.
Stable Diffusion, DALL-E, MidJourney, and Sora (video generation by OpenAI).
VAEs find their place in :
The generation of simple, stylized images.
The creation of synthetic data to drive other models.
Scientific fields, especially biology, chemistry or genetics.
A VAE encodes data in a probabilistic latent space, then reconstructs it from this space. This enables us not only to reproduce data close to the original, but also to explore new variations.
Simplicity of design and speed of training.
Ideal for exploring and manipulating latent representations, such as interpolating between two images or generating different versions of the same object.
Less costly than GAN or diffusion approaches.
Basic VAEs, or variants like VQ-VAE, often combined with other techniques.
GANs specialize in highly realistic image generation and visual transformation:
High-fidelity image creation.
Image translation: change style, add effects, transform one image into another.
Super-resolution: improving the quality of existing images.
GAN is a two-player game:
A generator that produces new images.
A discriminator that tries to distinguish these images from real data.
As training progresses, the generator becomes increasingly adept at creating content that is indistinguishable from the real thing.
Crisp, realistic results, especially on still images.
Faster training than broadcast models for certain tasks.
Less resource-intensive in targeted cases.
StyleGAN (exceptional photo quality), CycleGAN (image translation), BigGAN (large-scale, high-fidelity images).
Less well known to the general public, flows are used for :
High-quality audio and voice generation (vocoders).
Scientific and statistical modeling.
Applications requiring precise probability calculations.
A normalizing flow transforms a simple distribution (such as Gaussian noise) into a complex distribution corresponding to the real data. This process is reversible, allowing the probability of each sample generated to be calculated directly.
Allows precise control over the data generated.
Offers an explicit probabilistic density, which is useful for scientific or safety applications.
Less common than diffusion or GAN, but effective in certain contexts.
Glow, RealNVP, WaveGlow (audio vocoder).
👉 F ast playback :
LLM + RAG → standard for text and knowledge.
Broadcast → reference for high-quality images/videos.
VAE → exploratory, scientific, lighter.
GANs → efficient for targeted visual tasks.
Flows → used in audio and science
| Approach | Dominant uses | Strengths | Limitations |
|---|---|---|---|
| LLM + RAG (Large Language Models + Retrieval-Augmented Generation) | Text, code, chatbots, business assistants | – Hallucination reduction- Real-time knowledge updating- Highly versatile | – Dependence on the quality of document databases- High computational cost |
| Broadcast | Images, video, audio, 3D | – Visual/photo-realistic quality- Highly creative- Fine control (ControlNet, guidance) | – Very GPU-intensive- Generation time sometimes long- Ethical risks (deepfakes) |
| VAE (Variational Autoencoders) | Synthetic data, compression, scientific research | – Lightweight and quick to train- Interpretable latent spaces- Good for interpolation | – Less realistic than GAN/diffusion- Limited use in production |
| GANs (Generative Adversarial Networks) | High-fidelity images, super-resolution, style transfer | – Crisp, realistic results – Fast in certain cases (e.g. SR) – Well established in research | – Training instability – Collapse mode possible – Less flexible than diffusion |
| Flows (Normalizing Flows) | Audio (vocoders), scientific modeling, exact density | – Explicit probability- Reversible generation- Useful for audio and science | – Complex architectures- Less adopted than LLM/broadcasting |