Intelligence Artificielle
Gouvernance et IA responsable – Bank Privee
Publiée le octobre 21, 2025
Publiée le octobre 21, 2025
Les banques privées traitent des données sensibles (patrimoniales, fiscales, informations de santé) et doivent se conformer au RGPD, aux règles locales et à la directive européenne sur l’IA (AI Act). Pour accélérer l’innovation sans compromettre la vie privée, beaucoup de banque privée explorent des solutions permettant de prototyper des modèles sans utiliser de données réelles et de renforcer la gouvernance des modèles.
Classement de la maturité des différentes banques privées Européennes :
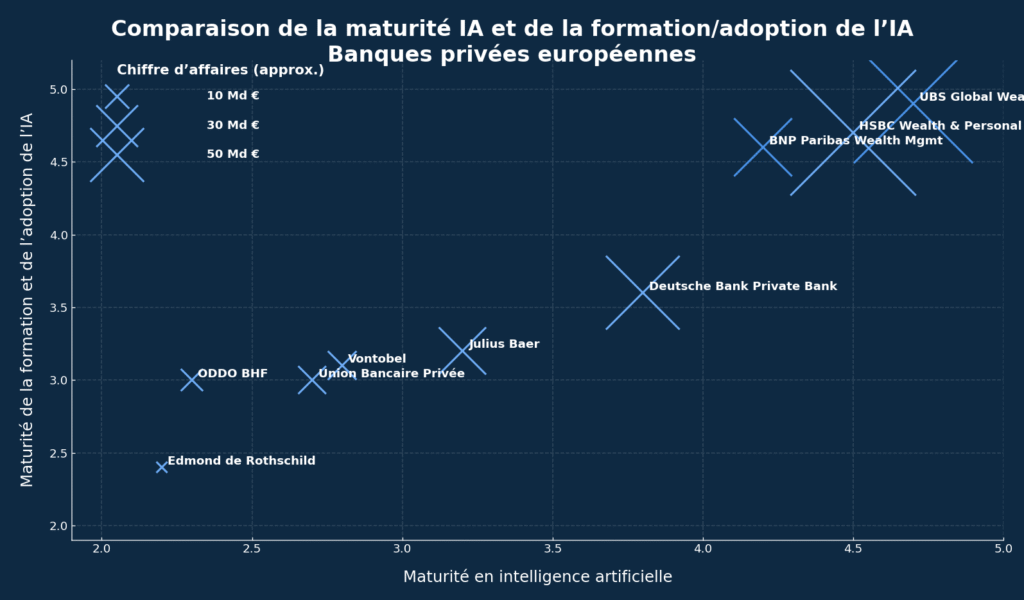
*Palmer Research Ressources, (estimatif à partir de donnée publiques) :
Axe horizontal (abscisse) : Maturité en intelligence artificielle.
C’est un score qualitatif (échelle de type 1 à 5, affichée ici ~2 à 5) qui synthétise le niveau technique : gouvernance de la donnée, modèles en production, outils IA (RAG, NLP, vision doc), intégrations SI, sécurité/RGPD, etc.
→ Plus on va vers la droite, plus la banque est techniquement avancée en IA.
Axe vertical (ordonnée) : Maturité de la formation et de l’adoption de l’IA.
Autre score qualitatif (même type d’échelle) qui mesure la diffusion réelle dans les équipes : formation des conseillers et des fonctions support, taux d’usage, conduite du changement, process, contrôles de conformité, etc.
→ Plus on monte vers le haut, plus l’IA est utilisée et maîtrisée par les équipes.
En novembre 2024, le spécialiste des logiciels analytiques SAS a acquis la technologie de données synthétiques de Hazy. L’objectif est d’intégrer la génération de données synthétiques dans la plateforme SAS Viya afin de permettre aux entreprises de créer des ensembles de données représentant fidèlement les distributions statistiques originales sans exposer d’informations identifiables. Le PDG de SAS, Jim Goodnight, souligne que cette technologie, classée parmi les meilleures de sa catégorie, offrira aux clients la possibilité de « harness data safely and effectively, enabling them to experiment and model scenarios previously out of reach ». IDC estime que les données synthétiques sont un « game changer » pour les secteurs soumis à des réglementations strictes, tels que la santé et la finance.
En parallèle, la start‑up autrichienne MOSTLY AI a lancé en janvier 2025 une SDK open source permettant de générer localement des données synthétiques. L’outil permet de former des générateurs de données différentielles privées et de produire des jeux de données partagés sans divulguer d’informations sensibles. La SDK propose des modèles de pointe (TabularARGN, LSTM) et des métriques de fidélité et de confidentialité intégrées.
Contrats de données : définir clairement qui peut accéder à quelles données et à quelles fins. Les projets d’IA doivent s’appuyer sur des jeux de données anonymisés ou synthétiques, avec un registre des accès.
Catalogue de données synthétiques : pour chaque cas d’usage (chatbot interne, moteur de recommandation, test de scoring), produire un jumeau synthétique du jeu réel. Les données synthétiques enrichies par SAS Data Maker ou MOSTLY AI peuvent être partagées entre équipes sans risque de violer la vie privée.
Fiches de modèles (model cards) : documenter l’objectif, les jeux de données utilisés (synthétiques ou réels), les performances, les biais potentiels et les mesures d’atténuation. Des tests d’alignement s’assurent que le modèle ne propose pas des conseils en investissement sans avoir toutes les informations nécessaires.
Surveillance et audites : mettre en place un monitoring continu pour détecter les dérives (drift). Un « red team » interne peut effectuer des attaques de prompt injection ou des tests d’adversarial afin de mesurer la résilience des systèmes.
Comité IA transverse : associer la direction des risques, la conformité, le juridique et les métiers pour valider les nouveaux projets IA. Ce comité évalue les avantages et les risques, approuve l’utilisation de données synthétiques et fixe des règles d’expérimentation.
Prototypage d’un copilote : générer un ensemble synthétique de documents clients et de notes internes, afin de développer un modèle RAG sans exposer de données personnelles. Les tests de synthèse permettent d’ajuster l’architecture et de valider la pertinence des réponses avant le déploiement.
Test des algorithmes de KYC/AML : créer des scénarios fictifs, incluant des structures complexes et des mouvements on‑chain, pour entraîner les modèles à reconnaître des schémas de fraude sans mobiliser les vrais comptes des clients.
Simulation de comportement client : dans le cadre de la personnalisation (article 3), les données synthétiques servent à simuler l’impact d’une recommandation (investir dans un fonds IA, souscrire une assurance‑vie) et à estimer la réaction du client sans utiliser de données réelles.
Les entreprises technologiques et bancaires accélèrent l’adoption de données synthétiques. SAS prévoit que d’ici 2026, 75 % des entreprises utiliseront l’IA générative pour produire des données clients synthétiques, contre moins de 5 % en 2023. La publication de la SDK de MOSTLY AI montre que la communauté open source s’empare de la question. Dans le secteur de la banque privée, des acteurs comme BNP Paribas et UBS se dotent de sandboxes où les modèles sont entraînés sur des données synthétiques afin d’éviter tout risque de fuite et de se conformer au RGPD.
La mise en place d’une gouvernance robuste des données et l’adoption de la synthèse de données représentent un saut qualitatif pour les banques privées. L’acquisition de Hazy par SAS et l’ouverture de la SDK de MOSTLY AI montrent que l’industrie s’organise pour fournir des outils respectant la confidentialité. En combinant ces approches avec un cadre de gouvernance rigoureux (contrats de données, model cards, comité IA), les banques priovées peuvent accélérer l’innovation tout en protégeant ses clients et en respectant la réglementation.